

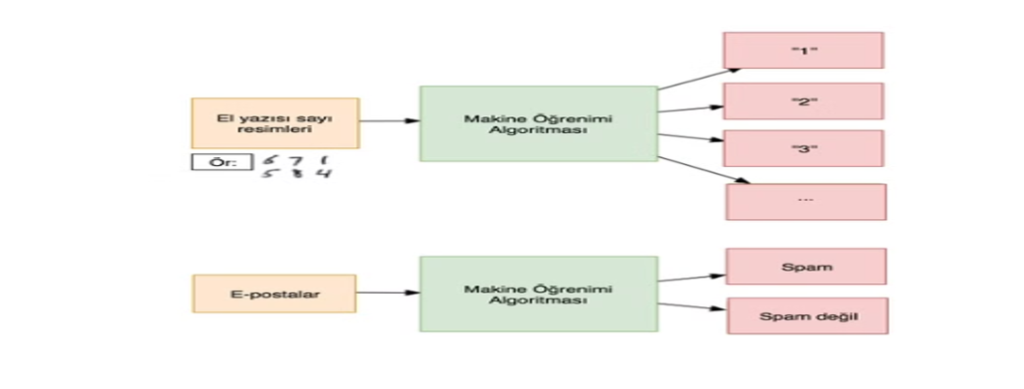
Makine öğrenmesi, sistemlerin açıkça programlanmadan verilerden öğrenmesini sağlayan bir yapay zeka alt dalıdır. Makine öğrenmesi algoritmaları, büyük veri kümelerinden örüntüler çıkararak tahminler yapar ve kararlar alır.
Makine öğrenmesi; veri bilimi, yapay zeka ve istatistiksel modelleme gibi disiplinlerle yakından ilişkilidir. Google, Amazon, Tesla gibi büyük teknoloji şirketleri, kullanıcı deneyimini iyileştirmek, otomasyon sağlamak ve büyük veriyi anlamlandırmak için ML modellerini aktif olarak kullanmaktadır.
Makine Öğrenmesi
Tükettikleri verilere göre öğrenen ya da performansı iyileştiren sistemler oluşturmaya odaklanan yapay zekâ alt kümesidir. Bilgisayarların belirli kurallar ve talimatlarla çalışmasını sağlayan yaklaşımdır.
Geleneksel Programlama ve Makine Öğrenmesinin Mantıksal Yapısı
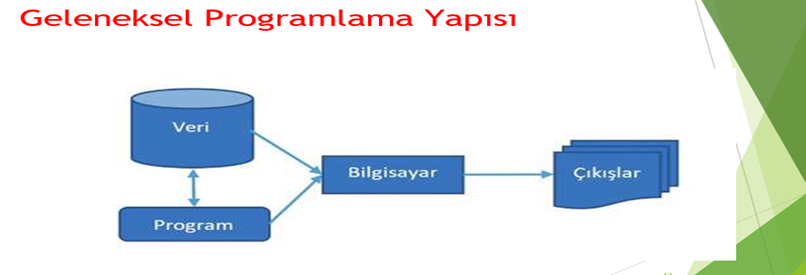
Bilgisayarların belirli kurallar ve talimatlarla çalışmasını sağlayan yaklaşımdır.
Mantığı şöyledir:
→ Programcı sorunları çözmek için kurallar yazar.
→ Bilgisayar bu kuralları kullanarak verilen girdileri ister.
→ Sonuç olarak belirlenen kurallara göre çıktı üretir.
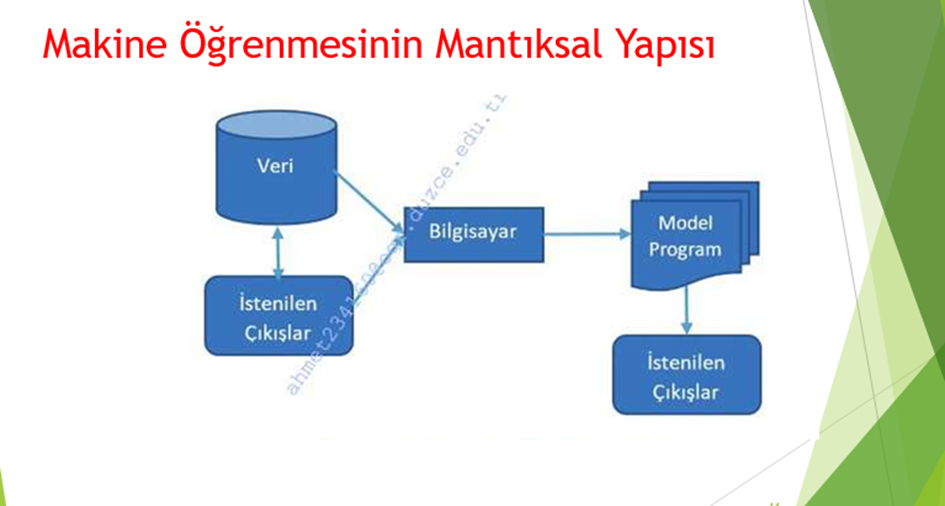
Makine Öğrenmesinin Mantıksal Yapısı
Daha önce makine öğrenmesini bir sistemin açık programlama yerine problemle ilgili veriler üzerinden çözümünü öğrenmesini mümkün kılan bir yapay zeka alt alanı olduğu belirtilmişti. Fakat şekilde de görüldüğü gibi o kadar da kolay değildir.
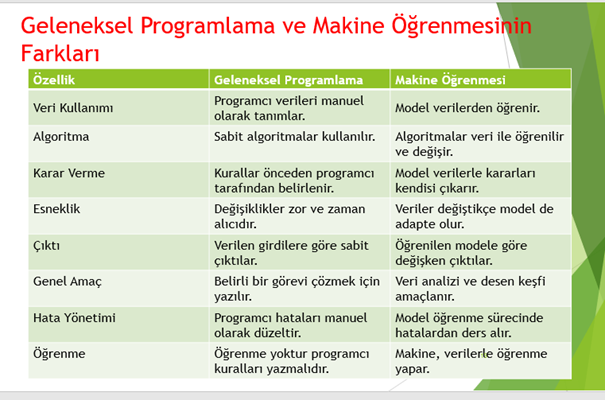
Geleneksel Programlama ve Makine Öğrenmesinin Farkları
Geleneksel programlama, belirli kurallar ve mantık dizileri kullanılarak geliştirilen yazılımları ifade eder. Bu yaklaşımda geliştirici, veriyi ve kuralları sisteme manuel olarak tanımlar ve sistem buna göre sonuç üretir. Yani, veri + kurallar → sonuç şeklinde işler.
Makine öğrenmesi ise, sisteme veriler ve sonuçlar verilerek, kuralların (modelin) bilgisayar tarafından öğrenilmesini sağlar. Bu yöntemde sistem, örneklerden yola çıkarak genelleme yapar ve yeni verilerle tahminlerde bulunur. Buradaki süreç veri + sonuç → model şeklindedir.
Temel fark, geleneksel programlamada kurallar insan tarafından yazılırken, makine öğrenmesinde bu kuralların (yani modelin) veriler aracılığıyla öğrenilmesidir. Bu sayede makine öğrenmesi, özellikle öngörülemeyen kalıpların veya büyük veri yığınlarının analizinde çok daha etkilidir.
Makine Öğrenmesi Teknikleri
En Yakın Komşu (K-NN) Tekniği: Yeni bir veri sınıflandırmak için ona en yakın “k” tane komşuya bakarız. Bu komşuların çoğunluğunu göre yeni veriyi oraya atarız.
Derin Öğrenme: Büyük miktarda verilen otomatik olarak özellikleri öğrenebilen ve tahmin yapabilen bir yöntemdir bilgisayarların insan beyni gibi öğrenmesine yardımcı olur.
Derin öğrenme, makine öğrenmesi yeteneklerini büyük ölçüde geliştirmiştir
Tom Mitchell’in Makine Öğrenmesi Tanımı;
Tanım şöyledir: «Bir bilgisayar programının performans P ile ölçülen T görevlerdeki performansı E deneyimi ile gelişiyorsa, bazı T görev sınıfları ve performans ölçütü P ile ilgili olarak deneyiminden öğrendiği söylenir.» görev (Task-T), deneyim (Experience-E), performans (Performace-P)
T (Görev): Programın yerine getirdiği iş veya problem
P (Performans Ölçütü): Görevin başarısını ölçmek için kullanılan kriter
E (Deneyim): Programın geçmiş veriler veya işlemlerle öğrendiği bilgi
- Aşağıda bazı popüler makine öğrenmesi tabanlı görevler açıklanmıştır.
- Sınıflandırma ya da ayrıştırma: Veri noktalarının belirli kategorilere ayrılması işlemidir. Regresyon ya da tahmin: Sürekli değerleri tahmin etmeye yönelik bir görevdir. Anormallik algılama: Normalden farklı olan, sıra dışı verileri tespit etmeye yönelik bir görevdir. Yapılandırılmış açıklama: Veri öğeleri arasındaki ilişkileri gösteren orijinal verilere açıklama olarak yapılandırılmış meta veriler eklemeyi içerir. Çeviri: Belirli bir dile ait girdiği veri örnekleri varsa bunu istenilen başka bir dile sahip çıktılara çevirebilir Kümeleme: Veriyi benzer özelliklere sahip gruplara ayırmaya yönelik bir yöntemdir.
- Transkripsiyonlar: Genellikle verilerin sürekli ve yapılandırılmamış çeşitli temsillerini gerektirir. Bunları daha yapılandırılmış ve ayrık veri öğelerine dönüştürür.
Etiketli Veri:
- Her verinin ne olduğu belirli ve açıklanmıştır. Model, giriş ve çıkış arasındaki ilişkiyi öğrenir.
Örnek: Kedi ve köpek resimleri içeren bir veri kümesinde, her resmin “kedi” veya “köpek” olarak etiketlenmesi. - Etiketsiz Veri:
Verilerde hangi kategoriye ait oldukları belirtilmemiştir. Model, veriyi gruplamaya çalışır.
Örnek: Müşterilerin alışveriş alışkanlıklarını analiz edip benzer davranışlara sahip grupları belirlemek.
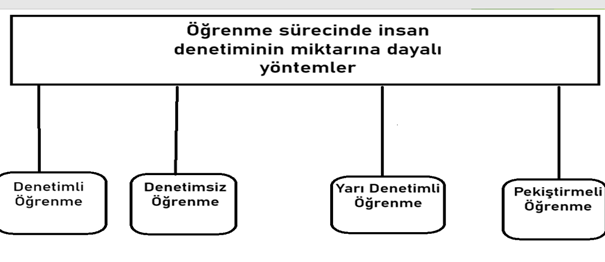
Denetimli makine öğrenmesi ile ilgili olarak öğrenme, belirli bir görev hakkında geçmiş deneyim için bir dizi örneğin kullanılması anlamına gelmektedir. Denetimli etiketli veridir ve sınıflandırma yapılabilir.
Denetimli öğrenmede veriler eğer hastalıklı-sağlıklı ya da kırmızı- yeşil gibi kategorilere ayrılmış, insan uzmanlar tarafından onaylanmış, etiketli ayrık hedef değişkeni gruplarına sahipse sınıflandırma görevlerinde kullanılırlar.
Eğer veriler finans dünyasında portföy değerleri gibi ya da bir hava durumu bilgileri gibi etiketli sürekli hedef değişkenlerine sahipse regresyon (ileriye dönük tahmin) işlemlerinde kullanılır.
Denetimsiz makine öğrenmesinde ise veriler etiketlenmemiştir. Bu etiketsiz veriler ile kümeleme ya da ilişkilendirme işlemleri yapılabilir. (ETİKETSİZ VERİ ODAKLIDIR)
Yarı denetimli makine öğrenmede ise hem etiketli hem de etiketsiz verilerle sınıflandırma, regresyon ya da kümeleme işlemleri yerine getirilebilir. (GÖREV VE VERİ ODAKLIDIR ETİKETLİ ETİKETSİZ)
Pekiştirmeli makine öğrenmesinde ise öğrenme, geçmiş deneyimlerden yapılır ve isabetli (doğru) kararlara ulaşmak için en uygun bilgiyi yakalamaya çalışır. Geçerli durumlar için doğru yapılan çıkarımlar ödül, yanlış yapılan çıkarımlar ceza olmak üzere deneme-yanılma işlemi ile görevler yerine getirilmeye çalışılır. (ÇEVRE ODAKLI YAKLAŞIMDIR)
Denetimli Öğrenme (Supervised learning)
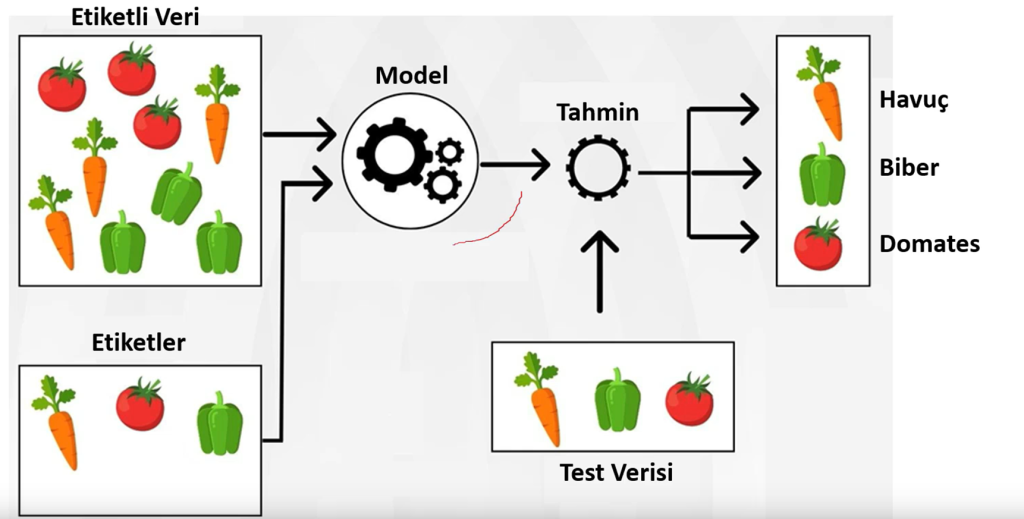
Denetimli öğrenme, sınıflandırma ve regresyon gibi makine öğrenmesi görevlerinde kullanılır. Bu yöntem, etiketli verilerle, algoritmaların doğru tahminler yapabilmesi için eğitim almasını sağlar. Örneğin, bir algoritma yıldız, üçgen ve beşgen gibi etiketlerle beslenerek, yeni görüntüleri ayırt edebilir. Regresyon, geçmiş verilerden gelecekteki olayları tahmin etmeye yönelik bir uygulamadır.
- Denetimli öğrenme, sınıflandırma ve regresyon gibi makine öğrenmesi görevlerinde kullanılır. Bu yöntem, etiketli verilerle, algoritmaların doğru tahminler yapabilmesi için eğitim almasını sağlar. Örneğin, bir algoritma yıldız, üçgen ve beşgen gibi etiketlerle beslenerek, yeni görüntüleri ayırt edebilir. Regresyon, geçmiş verilerden gelecekteki olayları tahmin etmeye yönelik bir uygulamadır.
- Denetimli öğrenmede, doğru hedeflere sahip bir eğitim seti sağlanır ve algoritma, bu verilere dayanarak genelleme yapar. Yaygın kullanılan denetimli öğrenme algoritmaları arasında destek vektör makineleri, lojistik regresyon, sinir ağları, rastgele ormanlar, K en yakın komşular ve karar ağaçları yer alır.
- REGRESYON: Bir emlak şirketi, geçmişteki ev satış verilerini (evin büyüklüğü, konumu, oda sayısı vb.) kullanarak, gelecekteki evlerin fiyatlarını tahmin etmek için bir regresyon modeli oluşturabilir. Burada hedef değişken (ev fiyatı) sürekli bir değerdir.
- Bir şirketin gelecekteki yıllık gelirini tahmin etmek.
- Bir ürünün satış rakamlarını tahmin etmek.
- SINIFLANDIRMA: Veriyi belirli kategorilere ayırmayı amaçlayan bir makine öğrenmesi görevidir.
- Bir e-posta uygulaması, gelen e-postaları “spam” ya da “ham” olarak sınıflandırmak için bir model kullanabilir. Bu durumda, her e-posta ya spam ya da ham (istenmeyen ya da istenen) olarak etiketlenir.
Denetimsiz Öğrenme (Unsupervised learning)
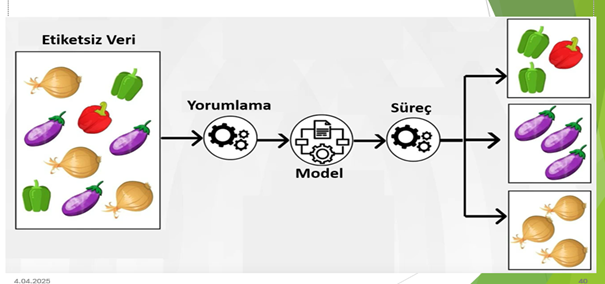
Denetimsiz öğrenme denetimli öğrenmedeki gibi önceden mevcut hedefi belirli eğitim verilerine dayanarak bazı sonuçları tahmin etmeye çalışmak yerine, verilerden anlamlı örüntüler ya da bilgiler çıkarmaya çalışmakla daha fazla ilgilenir. Denetimsiz öğrenmenin sonuçlarında daha fazla belirsizlik vardır, ancak yalnızca ham verilere bakarak bu modellerden daha önce görüntülenemeyen birçok bilgi de elde edilebilir. Denetimsiz öğrenme, etiketlenmemiş veri kümelerini insan müdahalesine, yani veri odaklı bir sürece ihtiyaç duymadan analiz ederken yaygın denetimsiz öğrenme görevlerine kümeleme, yoğunluk tahmini, özellik öğrenme, boyutsal azaltma, ilişkilendirme kuralları bulma, anormallik algılama örnek verilebilir.
Denetimsiz öğrenme genellikle işlem verileri için kullanılır. Büyük bir müşteri veri kümeniz ve satın alımlarınız olabilir, ancak insan yeterlikleriyle verilerde benzer olanları tespit edip, hızlı çıkartımlar yapmak neredeyse imkansızdır. Denetimsiz bir öğrenme algoritmasını besleyen bu verilerle, belirli bir yaş aralığındaki kokusuz sabun satın alan kadınların hamile olma ihtimalinin yüksek olduğu belirlenebilir ve bu nedenle satın alma sayısını artırmak için bu kitleye hamilelik ve bebek ürünleri ile ilgili bir pazarlama kampanyası hedeflenebilir.
Kümeleme ve İlişkilendirme Örnekleri
- 1. Kümeleme (Clustering) Örneği:
- Bir perakende şirketi, müşterilerini yaş, gelir ve alışveriş sıklığına göre gruplar. Bu sayede farklı müşteri segmentleri oluşturur.
- 2. İlişkilendirme (Association) Örneği:
- Bir süpermarket, süt ve ekmek gibi ürünlerin genellikle birlikte satın alındığını keşfeder ve bu bilgiyi satış stratejilerinde kullanır.
Yarı Denetimli Öğrenme Bir e-posta filtreleme sisteminde, sadece 100 etiketli spam e-posta var, ancak 10.000 etiketsiz e-posta bulunuyor
- Yarı denetimli öğrenme, hem etiketli hem de etiketsiz veriler içerir ve denetimli ile denetimsiz öğrenme yöntemlerinin birleşimidir. Gerçek dünyada etiketli veriler genellikle sınırlıyken, etiketlenmemiş veriler bolca bulunabilir. Bu durumda, yarı denetimli öğrenme devreye girer. Yöntem, etiketlenmemiş çok sayıda veri ve az sayıda etiketli veri kullanarak çalışır. Bu yöntemler, üretken, grafik tabanlı ve sezgisel tabanlı gibi farklı teknikler kullanabilir.
- Yarı denetimli öğrenme, genellikle az sayıda etiketli veriye dayalı denetimli bir model oluşturup, daha fazla etiketli örnek elde ederek bu modeli bu yeni verilere uygulamayı içerir. Ayrıca, benzer veri örneklerini kümelemek için denetimsiz algoritmalar kullanarak, insan yardımıyla bu kümelere etiket ekleyebilir ve bu bilgiyi gelecekteki model eğitiminde kullanabilirsiniz
ÖRNEK: Bir e-posta filtreleme sisteminde, sadece 100 etiketli spam e-posta var, ancak 10.000 etiketsiz e-posta bulunuyor. Yarı denetimli öğrenme, az sayıda etiketli veriyi kullanarak bir model oluşturur ve ardından etiketsiz verilerle modelin doğruluğunu artırmaya çalışır.
Pekiştirmeli Öğrenme= çevrenin geçerli durumunu gözlemleyerek belirli bir eylemde bulunur. (ÖDÜL CEZA İLİŞKİSİ)
Pekiştirmeli öğrenme yöntemleri, geleneksel denetimli ya da denetimsiz yöntemlerden biraz farklıdır. Genel olarak bu öğrenme aracı, çevre ile etkileşim için bir dizi strateji ya da politika ile başlar. Çevreyi gözlemlerken, bir kurala ya da politikaya dayalı olarak ve çevrenin geçerli durumunu gözlemleyerek belirli bir eylemde bulunur. Eyleme bağlı olarak etmen, zararlı olabilecek bir eylemde ceza ya da faydalı olabilecek bir eylemde ödül alır. Gerekirse mevcut politika ve stratejilerini günceller ve bu yinelemeli süreç, istenen ödülleri elde etmek için çevresi hakkında yeterince şey öğrenene kadar devam eder.
Örnek: Bir evcil köpeği eğitme örneği ele alalım: Mişa adındaki köpeğimizi bize top getirmesi için eğitiyoruz. Topu attıktan sonra Mişa’nın onu bize geri getirmesini istiyoruz. Mişa bu eylemi her yaptığında ödül veriyoruz. Bu şekilde Mişa, ilgili eylemin ve eylemi doğru yapmanın kendisine bir ödül getirdiğini öğrenir ve neticede işi doğru yapmaya alışır. Teknik olarak pekiştirmeli öğrenmede de aslında yapılan budur. Kaldı ki pekiştirmeli öğrenmede başlangıçta makinelerin daha iyi oyun oynayabilmesi için geliştirilmiş ve uygulanmıştır.
Pekiştirmeli öğrenme, çevredeki en uygun davranışı otomatik olarak değerlendirerek verimliliği artırmayı amaçlar. Yeni çözümler keşfetmek ile mevcut çözümleri kullanmak arasındaki dengeyi kurar ve robotik, otonom sürüş gibi alanlarda kullanılır.
Toplu Öğrenme= Bir e-posta sınıflandırma modelinin tüm e-posta verileriyle bir kerede eğitilmesi ve sonra yeni e-postalar için tahminler yapması toplu öğrenmeye örnektir.
Toplu öğrenme yöntemleri, modelin tüm eğitim verileriyle bir kez eğitildiği ve eğitim tamamlandığında modelin öğrenmeye devam etmediği yöntemlerdir. Eğitim süreci bittiğinde model, yeni verilerle tahminler yapmaya başlar. Bu yöntem, verilerin büyüdükçe daha fazla işlemci, bellek ve disk kaynağı gerektirdiği için sınırlı kapasiteye sahip sistemlerde kullanılmaz.
Örnek:
Bir e-posta sınıflandırma modelinin tüm e-posta verileriyle bir kerede eğitilmesi ve sonra yeni e-postalar için tahminler yapması toplu öğrenmeye örnektir.
Çevrimiçi Öğrenme
- Çevrimiçi öğrenme yöntemleri, eğitim verilerini artımlı gruplar (mini partiler) halinde algoritmaya besler. Bu yöntem, eğitim süreci tamamlandığında durmaz; model, yeni veri örnekleri geldikçe öğrenmeye devam eder. Çevrimiçi öğrenmenin avantajı, modelin sürekli olarak yeni verilerle öğrenmesi ve geçmiş verileri hatırlayarak yeniden eğitilmesine gerek olmamasıdır. Ancak, kötü veri örnekleri modelin performansını olumsuz etkileyebilir.
- Örnek:
Bir haber sitesi, kullanıcı davranışlarını çevrimiçi öğrenme yöntemiyle analiz eder ve sürekli olarak yeni kullanıcı verilerine göre içerik önerilerini günceller.
Örnek Tabanlı Öğrenme bir banka kredi başvurularını Eğer bu 3 başvurudan 2’si
Örnek tabanlı öğrenme, eğitim verileri üzerinde açık bir model oluşturmak yerine, yeni ve daha önce görülmemiş veri örneklerinin sonuçlarını tahmin etmek için ham veri noktalarını kullanan bir yaklaşımdır. Örneğin, K-en yakın komşu algoritmasında, model yeni bir veri noktası için en yakın üç eğitim verisini bulur ve bu noktaların çoğunluklarına göre tahmin yapar. Bu süreç, mesafe ölçütleri (örneğin, Öklid veya kosinüs mesafesi) kullanarak veri noktaları arasındaki benzerlikleri değerlendirir ve genelleme yapar.
Örnek Tabanlı Öğrenme Örneği
- Diyelim ki, bir banka kredi başvurularını onaylamak için bir sistem kullanıyor. Eğitim verilerinde, her başvurunun gelir, kredi geçmişi ve kredi onayı gibi bilgileri var.
- Yeni bir başvuru geldiğinde, örnek tabanlı öğrenme kullanarak, geçmişte benzer başvurularda ne olduğu gözlemlenir. Yeni başvurunun özelliklerine en yakın 3 başvuru bulunur (örneğin, gelir ve kredi geçmişi benzer olanlar). Eğer bu 3 başvurudan 2’si “onay” aldıysa, yeni başvuru da “onay” olarak sınıflandırılır.
Model Tabanlı Öğrenme
Örnek: Bir ev fiyatı tahmin modeli oluşturduğumuzu düşünelim. Model, evin büyüklüğü, oda sayısı, konumu gibi özellikleri kullanarak, bu parametreler üzerinde genelleme yapar. Eğitim verisiyle model parametrelerini optimize ettikten sonra, doğrulama verileriyle test edilerek en iyi model seçilir. Seçilen model, yeni evlerin fiyatlarını tahmin etmek için kullanılabilir.
Model tabanlı öğrenme, makine öğrenmesinde, verilerin özelliklerinden genelleme yaparak bir model oluşturma yaklaşımıdır. Bu yöntem, eğitim verilerini kullanarak modelin parametrelerini optimize eder ve en iyi modelin doğrulama ve test verileriyle sınanarak seçilmesini sağlar. Sonrasında, bu model tahminlerde bulunmak ya da kararlar almak için kullanılır.
Makine Öğrenmesinin Avantajları ve Faydaları
Birincisi makine öğrenmesinin, bir programcının bilgisayara yerleştiremeyeceği kadar karmaşık görünen her türlü̈ görevi halledebilmesi anlamına geldiği gerçeğidir.
İkincisi ise yapılması gereken tüm farklı görevleri uyarlamalı bir şekilde oluşturmak için makine öğrenmesinden elde edilecek çıktıların kullanabileceği fikridir
Makine öğrenmesinin en büyük avantajlarından biri, eğilimleri ve örüntüleri tanımlamayı inanılmaz derecede basit hale getirmesidir.
Her şeyden önce, makine öğrenmesi programları verileri değerli bilgilere dönüştürebilir. Bu ister finansal iyileştirme ve kârı artırma, ister tıbbi ve insani anlayış için olsun, farklı yaklaşımlara ilişkin anlayışı geliştirmek için verilerin gizli bilgileri ve örüntüleri ortaya çıkarmasını sağlayan makine öğrenmesinin arkasındaki temel fikirdir.
Makine öğrenmesi, insan müdahalesi olmadan verilerden öğrenir ve deneyim kazandıkça doğruluğunu artırır. Veri miktarı arttıkça algoritmalar daha doğru tahminler ve kararlar üretir
Makine öğrenmesinin en büyük avantajlarından biri de çok değişkenli ve çok boyutlu veri kümelerini işleyebilme yeteneğidir.
Makine öğrenmesi nasıl alışveriş yapılacağından, tıbbi hastalıkları nasıl teşhis edip, tedavi edileceğine ve hatta hükümet programlarını uygulamaya kadar her konuda devrim yaratabilir. Modern dünyadaki hemen hemen her şeyi iyileştirmek için kullanılabilir
Makine Öğrenmesi Dezavantajları ve Zorlukları
Ana dezavantajı iyi kalitede ve tarafsız büyük veri seti elde etme ihtiyacıdır. Bir makine öğrenmesi yaklaşımı uygulamanın sonuçlarını yorumlama ve hassas hataları tespit etme gibi bazı zorluklara sahiptir. Makine öğrenmesi verilerden değerli bilgiler çıkarabilir, ancak bu bilgilerin doğru yorumlanmaması yararsızdır. Ayrıca, veri yanlılığını tespit edememesi yanıltıcı ve hatalı sonuçlara yol açabilir. Makine öğrenmesinin başarımı, eğitim verilerinin kalitesine ve seçilen modele bağlıdır. Başarısızlığa yol açabilecek faktörler arasında yetersiz veya çarpık veriler, aşırı ya da yetersiz uyumlama ve test verisi eksikliği yer alır.
Makine Öğrenmesi Uygulamaları
Veri Madenciliği:
Büyük veri kümeleri içindeki gizli kalıpları, ilişkileri ve anlamlı bilgileri keşfetmeye yarayan süreçtir.
Tahmine Dayalı Analitik:
Geçmiş verilere dayanarak gelecekteki eğilimleri, davranışları veya sonuçları öngörmeyi amaçlayan analiz yöntemidir.
Dolandırıcılık Tespiti:
Makine öğrenmesi, olağan dışı işlem kalıplarını analiz ederek dolandırıcılık girişimlerini gerçek zamanlı tespit edebilir.
Müşteri Gruplandırma:
Algoritmalar, benzer davranışlara sahip müşterileri segmentlere ayırarak kişiselleştirilmiş pazarlama stratejileri oluşturulmasını sağlar.
Web Sayfası Optimizasyonu:
Kullanıcı davranışlarını analiz ederek sayfa tasarımının ve içerik yerleşiminin daha etkili hale getirilmesini sağlar.
Ürün Önerileri:
Kullanıcıların geçmiş davranışlarını inceleyerek ilgi duyabilecekleri ürünleri önerir.
Pazarlama:
Makine öğrenmesi, kampanya başarı oranlarını tahmin eder ve hedef kitleye en uygun mesajların belirlenmesine yardımcı olur.
Finans:
Risk analizi, kredi skorlama ve yatırım tahminleri gibi finansal karar süreçlerini destekler.
Sağlık:
Hastalık teşhisi, tedavi önerisi ve medikal görüntü analizi gibi alanlarda doğru ve hızlı çözümler sunar.
Görüntü Tanıma:
Fotoğraf veya videolardaki nesneleri, yüzleri veya durumları otomatik olarak tanımlar.
Operasyonlar:
Stok yönetimi, talep tahmini ve üretim planlamasında verimliliği artırır.
Veri Güvenliği ve Anormallik Tespiti:
Sistemlerdeki olağandışı davranışları tespit ederek siber saldırılara karşı erken uyarı sağlar.
Konuşma Tanıma:
İnsan sesini yazıya dökerek sesli komut sistemlerinin ve asistanların çalışmasını sağlar.
Arama Motorları:
Makine öğrenmesi, arama motorlarında da kullanılır. Program, verilen yanıtlardan veya sorgulardan öğrenerek zamanla daha iyi yanıtlar vermeye çalışır.
PERFORMANS ÖLÇÜTLERİ NEDİR?
Makine öğrenmesinde performans, bir modelin belirli bir görevi yerine getirme yeteneğini ve doğruluğunu ölçen bir kavramdır. Modelin performansı, genellikle modelin ne kadar doğru, hızlı ve verimli olduğuna dair ölçütlerle değerlendirilir. Bu ölçütler, modelin gerçek dünya verileri üzerine ne kadar iyi çalıştığını anlamamıza yardımcı olur.
Bu ölçümler genellikle algoritmanın deneyim E’yi kazanmak için kullandığı, eğitim veri örnekleri ile daha önce modelin hiç görmediği veya öğrenmediği, genellikle doğrulama ve test veri örnekleri olarak bilinen veri örnekleri üzerinde değerlendirilir.
Bir makine uygun bir şekilde ilgili göreve ait veri ile beslenirse, yine uygun bir makine öğrenmesi modelini kullanarak bu makineyi verileri nasıl yorumlayacağı, işleyeceği ve analiz edeceği öğretilerek deneyim kazandırılabilir. Oluşturulan bu modelin çıktıları ne kadar iyi öngördüğü ya da ne kadar iyi tahmin yapabildiği yine uygun performans ölçütleri ile test edilebilir.
Sonuç olarak bir makine öğrenmesi süreci, makineye çok sayıda belirli bir görevi gerçekleştirmek için gerekli olan geçmiş veriler ile besleyerek başlar. Daha sonra makine gizli bilgileri, özellikleri durumları ve örüntüleri tespit etmek için bu veriler üzerinden herhangi bir öğrenme algoritması ile eğitilir.
Sınıflandırmada yaygın kullanılan performans ölçütleri, arasında doğruluk (accuracy), kesinlik (precision), hatırlatma(recall), F1 puanı(F1 score), duyarlılık(sensitivity), özgüllük(specificity), hata oranı(error rate), yanlış sınıflandırma oranı (misclassification rate) gibi ölçütler sayılabilir.

Doğruluk (Accuracy)
“100 hastanın kaçını gerçekten hasta gerçekten hasta değil olarak tahmin etmiş onun oranını açıklar.“
- Sınıflandırma problemlerinde, modelin doğru tahmin ettiği örneklerin tüm örneklere oranıdır.
- «Model genel olarak ne kadar iyi» , «Modelin toplamda kaç tane doğru tahmin yaptığını gösterir.»
- Formülü ise şöyledir:
- Örnek olayla çözersek;
- (7+89) / 100 = 0,96
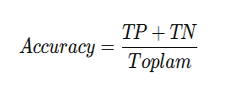
Kesinlik (Precision)
“Modelin hasta dediği kişilerin gerçekten hasta olma oranıdır.” Pozitif olarak tahmin edilen örneklerin gerçekte pozitiflere oranı.
- Pozitif olarak tahmin edilen örnekler içinde gerçekten pozitif olanların oranıdır.
- Modelin «kanser var» dediği kişilerin gerçekten kanser olma oranını gösterir.
- Yani «Model kanser var dediğinde ne kadar doğru?» Bunu ölçeriz.
- Formülü ise şöyledir:
- Örnek olayla çözersek; 7/(7+3) = 0,7
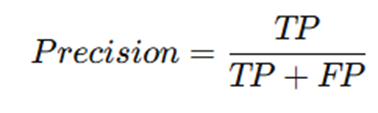
Hatırlatma (Recall) ve Duyarlılık (Sensitivity)
Gerçek hastaların ne kadarını yakaladık. Gerçekte hasta olan örneklerin, modelin hasta olarak tahmin edilen örneklere oranı. Modelin gerçeklere kadar yaklaştığını gösterir.
- Gerçek pozitifleri (TP) doğru bir şekilde tahmin etme oranıdır.
- Gerçekten kanser olan hastaların kaçını doğru bulduğumuzu gösterir.
- Aynı zamanda «Hastaları tespit etme oranı» da diyebiliriz.,,
- Formülü şöyledir:
- Örnek olayla çözersek; 7/(7+1) = 0,87
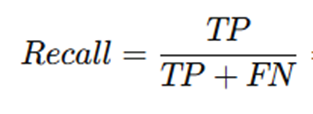
F1 puanı(F1 score)
Precision ve Recall arasındaki dengeyi ölçen harmonik ortalama metriğidir.
Formülü şöyledir:
Örnek olayla çözersek; 2 * {(0,7*0,87) / (0,7+ 0,87)} =0,60/1,57
= 0,38
= 0,38 * 2 = 0,76
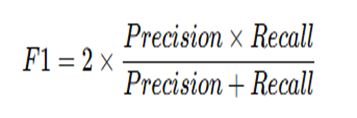
Özgüllük (Specificity)
Negatif sınıfa ait örnekleri (TN) doğru bir şekilde tahmin etme oranıdır.
Formülü şöyledir:
Örnek olayla çözersek; 89 / (89+ 3) = 0,96
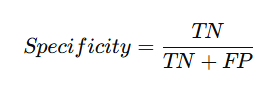
Roc Eğrisi ve AUC Değeri
Sınıflandırma modeli performansı yukarıdaki ölçütlerle değerlendirilebileceği gibi görselleştirilerek de değerlendirilebilir.
Çoğu zaman karışıklık matrisinden hesaplanan son nicel ölçütler, modelin performansını değerlendirilmesine izin vermez.
s
Hata Oranı (Error Rate)
Modelin yanlış tahmin ettiği pozisyon oranıdır.
Formülü ise şöyledir:
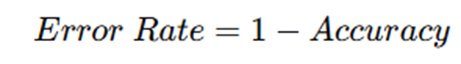
Örnek olayla çözersek; 1 – 0,96 = 0,04
Yani demek oluyor ki model 100 pozisyonun 4’ünde yanlış karar vermiş.
s
Yanlış Sınıflandırma Oranı (Misclassification Rate)
Modelin yaptığı tüm yanlış tahminlerin toplam veri içindeki oranıdır.
Formülü ise şöyledir:
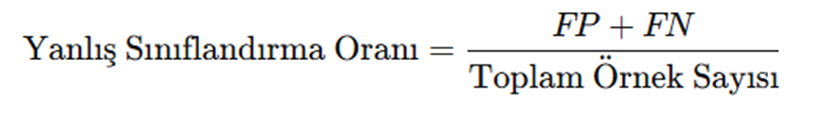
Örnek olayla çözersek; (3+1)/100 = 0,04
Makine Öğrenmesine Giriş: Süreç ve Modeller
Bu bölümde makine öğrenmesi temel süreçlerini, modelleme aşamalarını ve çeşitli uygulama alanlarını keşfedeceğiz. Makine öğrenmesi, bilgisayarların verilerden öğrenmesini ve bu öğrenmeyle gelecekteki olayları tahmin etmesini sağlayan güçlü bir teknoloji haline geldi. Günümüzde sağlık, finans, ulaşım ve daha pek çok sektörde yaygın olarak kullanılmaktadır.
Makine Öğrenmesi Süreci Adımları
Başlangıçta, çözülmesi gereken iş problemi net bir şekilde tanımlanmalı ve hedefler belirlenmelidir. Bu süreçte, başarı kriterleri (doğruluk, kesinlik gibi) ve çözümün sağlayacağı iş değeri analiz edilmelidir.
Daha sonra, problem için gerekli veriler belirlenir ve toplanır. Bu aşamada verilerin türleri, kaynakları, toplama yöntemleri ve gizlilik konuları ele alınır. Verilerin kalitesi ve miktarı da modelin performansı için büyük önem taşır.
Toplanan veriler hazırlanır ve analiz edilir. Bu adımda verilerin temizlenmesi, dönüştürülmesi, örneklemesi ve ayrıştırılması gibi işlemler yer alır. Ölçeklendirme ve boyut indirgeme teknikleri de uygulanabilir.
Hazırlanan verilerle uygun bir model seçilir ve eğitilir. Modelin performansı değerlendirilir ve iyileştirilir. Son olarak, eğitilmiş model kullanılır ve performansı düzenli olarak izlenir.
Problemin Belirlenmesi ve Anlaşılması
- Bir e-ticaret sitesi için müşteri kaybını tahmin etme problemi, makine öğrenmesinin nasıl kullanılabileceğine dair iyi bir örnektir.
- İş problemi, müşterilerin neden siteyi terk ettiğini anlamak ve bu ayrılımları önlemektir. Hedef, müşteri kaybını doğru bir şekilde tahmin etmek ve bu bilgiye dayalı olarak müşteri deneyimini geliştirmektir.
- Bu çözüm, müşteri kaybını azaltarak daha yüksek müşteri sadakati ve artan gelir sağlayabilir. Mevcut çözümler (örneğin, anketler) ve makine öğrenmesinin sağladığı avantajlar değerlendirilmelidir.
Veri Kalitesi ve Miktarı
- Veri kalitesi, modelin performansını doğrudan etkiler. Doğruluk, eksiksizlik, tutarlılık ve güncellik önemli faktörlerdir.
- Yeterli veri miktarı, modelin genelleme yeteneği için kritiktir. Büyük örneklem büyüklüğü, modelin farklı veri setlerinde iyi performans göstermesini sağlar.
- Veri kalitesini ölçme yöntemleri arasında veri profili oluşturma, aykırı değer analizi ve boş değer analizi bulunur. Kaliteyi artırmak için veri temizleme, dönüştürme ve tamamlama teknikleri kullanılabilir.
- İdeal veri seti boyutu, probleme ve model karmaşıklığına bağlı olarak değişir ancak genellikle 1000’lerce kayıt yeterli kabul edilir.
Veri Hazırlama ve Analiz Etme
- Kayıp verilerin ele alınması (boş değerlerin doldurulması veya silinmesi) modelin performansını etkileyebilir. Aykırı değerler, modelin doğruluğunu azaltabilir.
- Kategorik veriler, sayısal verilere dönüştürülmeli ve metin verileri vektörleştirilmelidir. Bu dönüşümler, modelin verileri daha kolay işlemesini sağlar.
- Büyük veri setlerinde örnekleme kullanılarak modelin eğitim süresi azaltılabilir. Dengesiz veri setlerinde dengeleme teknikleri, modelin farklı sınıflara karşı önyargılı olmamasını sağlar.
- Veriler, eğitim, doğrulama ve test setlerine ayrılır. Eğitim seti modelin eğitimi için kullanılır, doğrulama seti hiperparametre optimizasyonu için ve test seti modelin genelleme yeteneğini değerlendirmek için kullanılır.
Modelin Kullanımı ve İzlenmesi
Eğitilmiş model, canlı ortama taşınır (deployment) ve performansı düzenli olarak izlenir. Modelin doğruluk ve diğer metrikleri zaman içinde takip edilir. Veri dağılımındaki değişikliklere uyum sağlamak için model yeniden eğitilebilir. Yeni algoritmalar veya özellikler eklenerek model güncellenebilir. Sonuçlar raporlanır ve iş paydaşlarına sunulur.
Veri Biliminde Eğitim ve Test Kümeleri

s
Veri biliminde model geliştirme sürecinde eğitim ve test kümelerinin önemi, model başarısının anahtarıdır. Bu sunum, etkili bir modelleme için veri ayırma, model seçimi, eğitim, değerlendirme ve iyileştirme adımlarını ele alıyor.
Eğitim ve Test Verilerinin Belirlenmesi
Eğitim Kümesi (train)
- Modeli eğitmek için kullanılan veri seti (%70-80 önerilir)
Test Kümesi (test)
Modelin performansını değerlendirmek için kullanılan veri seti (%20-30 önerilir)
Model Seçimi: Farklı Modeller ve Algoritmalar

Sınıflandırma Algoritmaları
Lojistik regresyon, destek vektör makineleri (SVM), karar ağaçları, Random forest, sinir ağları

Regresyon Algoritmaları
Doğrusal regresyon, polinom regresyon, destek vektör regresyonu (SVR), karar ağaçları, Random forest
Kümeleme Algoritmaları
K-ortalama (K-means), hiyerarşik kümeleme
s
Modelin Eğitimi: Eğitim Süreci

- Veri Önişleme
Eksik verilerin giderilmesi, aykırı değerlerin temizlenmesi, özellik ölçeklendirme
- Modelin Eğitimi
Algoritmanın eğitim verileri üzerinde parametreleri öğrenmesi
- Kayıp Fonksiyonu
Modelin ne kadar iyi performans gösterdiğini ölçmek için kullanılır
Model Değerlendirme: Performans Değerlendirmesi
Model İyileştirme: İyileştirme Yöntemleri

Sonuç
Eğitim ve test kümelerine ayırma, veri bilimi projelerinde model geliştirme sürecinin kritik bir adımıdır. Doğru veri ayrımı, model seçimi, eğitim, değerlendirme ve iyileştirme adımları, başarılı bir model oluşturmanın temelini oluşturur.
Özellik Seçimi ve Mühendisliği

Özellik seçimi yöntemleri, filtre, sarmalayıcı ve gömülü yöntemleri içerir.

Özellik mühendisliği, mevcut özelliklerden yeni özellikler türetmeyi ve mevcut özellikleri dönüştürmeyi içerir.

Alan bilgisi ve uzman görüşleri, özellik seçimi ve mühendisliği için önemlidir.
Algoritma Seçimi ve Model Eğitimi
Makine öğrenmesi algoritmaları regresyon, sınıflandırma ve kümeleme gibi görevler için kullanılır.

1
Algoritma seçimi, veri tipi, problem tipi ve doğruluk gereksinimlerine bağlıdır.

2
Model eğitimi, verileri eğitim ve test kümelerine ayırma, parametre optimizasyonu ve modelin eğitilmesini içerir.

s
s
Model Değerlendirme
Model değerlendirmesi, doğruluk, kesinlik, geri çağırma, F1 skoru ve AUC gibi metrikleri kullanır.

1
Çapraz doğrulama teknikleri, modelin genel performansını ölçer.

2
K-katlı çapraz doğrulama gibi teknikler, modelin veri kümesindeki değişikliklere karşı direncini değerlendirir.
Model Ayarı ve Düzenlemesi
Hiperparametre optimizasyonu, grid arama, rastgele arama ve Bayes optimizasyonu gibi yöntemleri kullanır.
1
Aşırı öğrenme ve yetersiz öğrenme sorunları, modelin eğitim verilerine aşırı uyum sağlaması veya yeterince uyum sağlayamaması anlamına gelir.

2
Düzenleme teknikleri, L1 ve L2 düzenleme gibi, aşırı öğrenmeyi önlemek için kullanılır.
Model Kullanımı ve Tahmin
Eğitilmiş model, yeni veriler üzerinde tahmin yapabilir ve sonuçları analiz etmek için kullanılabilir.
- -Tahminler, modelin çıktısını temsil eder ve gerçek dünyadaki olayları anlamak için kullanılabilir.
- -Tahmin sonuçları, görselleştirme araçları ile daha iyi anlaşılabilir.
Gerçek Dünya Uygulamaları
Tahmin ve çıkarım, finans, sağlık, pazarlama, üretim, perakende gibi çeşitli sektörlerde kullanılmaktadır.

Ürün öneri sistemi, satışları %30’a kadar artırdı.
Sonuç ve Gelecek Perspektifleri
Makine öğrenmesi modelleri, tahmin ve çıkarım alanında önemli bir potansiyele sahiptir. Yapay zeka ve derin öğrenme alanındaki gelişmeler, daha sofistike tahmin modelleri yaratmaya devam ediyor.

Makine Öğrenmesi Modellerinde Kullanılan Python Kütüphaneleri
Makine öğrenmesi projelerinde kullanılan temel Python kütüphanelerine genel bakış. Bu bölüm, bu kütüphanelerin işlevlerini ve kullanım alanlarını açıklayacaktır.